Made in London by me
Phil’s Data Structure Zoo
Solving a problem programatically often involves grouping data items together so they can be conveniently operated on or copied as a single unit – the items are collected in a data structure. Many different data structures have been designed over the past decades, some store individual items like phone numbers, others store more complex objects like name/phone number pairs. Each has strengths and weaknesses and is more or less suitable for a specific use case. In this article, I will describe and attempt to classify some of the most popular data structures and their actual implementations on three different abstaction levels starting from a Platonic ideal and ending with actual code that is benchmarked:
- Theoretical level: Data structures/collection types are described irrespective of any concrete implementation and the asymptotic behaviour of their core operations are listed.
- Implementation level: It will be shown how the container classes of a specific programming language relate to the data structures introduced at the previous level – e.g., despite their name similarity, Java’s Vector is different from Scala’s or Clojure’s Vector implementation. In addition, asymptotic complexities of core operations will be provided per implementing class.
- Empirical level: Two aspects of the efficiency of data structures will be measured: The memory footprints of the container classes will be determined under different configurations. The runtime performance of operations will be measured which will show to that extend asymptotic advantages manifest themselves in concrete scenarios and what the relative performances of asymptotically equal structures are.
Theoretical Level
Before providing actual speed and space measurement results in the third section, execution time and space can be described in an abstract way as a function of the number of items that a data structure might store. This is traditionally done via Big O notation and the following abbrevations are used throughout the tables:
- C is constant time, O(1)
- aC is amortized constant time
- eC is effective constant time
- Log is logarithmic time, O(log n)
- L is linear time, O(n)
The green, yellow or red background colours in the table cells will indicate how “good” the time complexity of a particular data structure/operation combination is relative to the other combinations.
Table 1
<?xml version=”1.0” encoding=”UTF-8”?>
| Performance characteristics of core operations |
| |||||||||
Data Structure |
Configurability | (Random) Access | Search | Insertion | Deletion | Space | |||||
⊘ | Worst | ⊘ | Worst | ⊘ | Worst | ⊘ | Worst | ||||
Wasted space ⊘ | Worst space complexity | ||||||||||
Linear Data Structures: | |||||||||||
----- | C | Linear L Binary (sorted) Log | ------ | Zero | L | ||||||
Initial capacity | at beginning/middle: L at end: aC | L | L | ||||||||
----- | C | √ L | L | ||||||||
----- | L | L | at beginning/end: C last element unknown (singly): L in middle: search time + C | L | L | ||||||
promotion probability | Log | L | Log | L | Log | L | Log | L*Log | L*Log | ||
Associative Arrays/Hashes: | |||||||||||
load factor; hash function; collission resolution strategy | ----- | C | L | C | L | C | L | L | L | ||
size / probability of false positives | ----- | C | C | ----- | Zero | C | |||||
Trees: | |||||||||||
Trie with average key length k | O(k) | O(k) | O(k) | O(k) | O(kn) | O(kn) | |||||
| find min/max: C | L | Log | Log | L | L | |||||
----- | Level-order Traversal (BFS) |
Log |
L |
Log |
L |
L |
L | ||||
Log | L | Log | L | ||||||||
Balanced STs: | ----- | Log | Log | Log | Log | L | L | ||||
Number of node elements | |||||||||||
| |||||||||||
| --- | Log | L | Log | L | Log | L | L | L | ||
| Log | L | L | ||||||||
Graphs: | |||||||||||
Graph with V nodes and E edges | V&E management: | Breadth First Search or Depth First Search: O(|E| + |V|) Shortest path + Min-heap: O( (|V|+|E|) log |V| ) Shortest path + Array: O(|V|2) Bellman-Ford: O(|V| * |E|) | Vertex: C Edge: C | Vertex: O(|V| + |E|) Edge: O(|E|) | O(|V| + |E|) | ||||||
Vertex/Edge: O(|E|) | |||||||||||
Vertex: O(|V|2) Edge: C | O(|V|2) | ||||||||||
O(|V| * |E|) | O(|V| * |E|) | ||||||||||
The first five entries of Table 1 are linear data structures: They have a linear ordering and can only be traversed in one way. By contrast, Trees can be traversed in different ways, they consist of hierarchically linked data items that each have a single parent except for the root item. Trees can also be classified as connected graphs without cycles; a data item (= node or vertex) can be connected to more than two other items in a graph.
Data structures provide many operations for manipulating their elements. The most important ones are the following four core operations which are included above and studied throughout this article:
- Access: Read an element located at a certain position
- Search: Search for a certain element in the whole structure
- Insertion: Add an element to the structure
- Deletion: Remove a certain element
Table 1 includes two probabilistic data structures, Bloom Filter and Skip List.
Implementation Level – Java & Scala Collections Framework
The following table classifies almost all members of both the official Java Collection and Scala Collection libraries in addition to a number of relevant classes like Array or String that are not canonical members. The actual class names are placed in the second column, a name that starts with im. or m. refers to a Scala class, other prefixes refer to Java classes. The fully qualified class names are shortened by using the following abbreviations:
- u. stands for the package java.util
- c. stands for the package java.util.concurrent
- lang. stands for the package java.lang
- m. stands for the package scala.collection.mutable
- im. stands for the package scala.collection.immutable
The actual method names and logic of the four core operations (Access, Search, Addition and Deletion) are dependent on a concrete implementation. In the table below, these method names are printed right before the asymptotic times in italic (they will also be used in the core operation benchmarks later). For example: Row number eleven describes the implementation u.ArrayList (second column) which refers to the Java collection class java.util.ArrayList. In order to access an item in a particular position (fourth column, Random Access), the method get can be called on an object of the ArrayList class with an integer argument that indicates the position. A particular element can be searched for with the method indexOf and an item can be added or deleted via add or remove.
Scala’s closest equivalent is the class scala.collection.mutable.ArrayBuffer which is described two rows below ArrayList: To retrieve the element in the third position from an ArrayBuffer, Scala’s apply method can be used which allows an object to be used in function notation, Ss we would write val thirdElement = bufferObject(2). Searching for an item can be done via find and appending or removing an element from an ArrayBuffer is possible by calling the methods += and -= respectively.
Table2
<?xml version=”1.0” encoding=”UTF-8”?>
Data Structure(s) | Implementation | Super Power(s) | (Random) Access | Search | Addition | Deletion |
Java Array | Scala Array <w) | Cache friendly; primitive support | [] C apply C | custom function L find L | ----- | ||
m.ArraySeq | Polymorphy, backed by an Array[AnyRef] | apply C | find L | ----- | ||
u.EnumSet | For Enum keys; high performance | ----- | contains C | add C | remove C | |
EnumMap | For Enum keys; high performance | get C | containsKey C | put C | remove C | |
c.ArrayBlockingQueue | FIFO; bounded | peek C | contains L | offer C | poll C | |
String | Immutable; char Array internally | apply C | indexOf L | += L | replace L | |
Array
| lang.StringBuffer | Thread-safe | charAt C | indexOf L | append C | delete L |
lang.StringBuilder | m.StringBuilder <w) | Not synchronized; faster than lang. StringBuffer | |||||
u.Vector | u.Stack <e) | Synchronized; LIFO prefer u.ArrayDeque | get C elementAt C | contains C search L | addElement C push C | remove C pop C | |
u.ArrayList | FIFO & LIFO | get C | indexOf L | add aC | remove L | |
u.ArrayDeque | FIFO & LIFO; implements Deque | peek C | contains L | offer aC | remove L poll C | |
m.ArrayBuffer | Cache friendly for iteration; all Array ops available with similar speed | apply C | find L | += (append) aC +=: (prepent) L | -= L | |
m.ArrayStack | LIFO | apply C | find L | push aC | pop C | |
u.BitSet | Array of 64-bit Longs, fast operations for small number of Longs | get C | set C | andNot C | ||
im.BitSet m.Bitset | ----- | contains C | + L add aC | - L remove C | ||
Copy-on-write Array | c.CopyOnWriteArrayLis | c.CopyOnWriteArraySet <w) | Thread-safe; immutable Frequent iteration, read-only ops | get C ----- | indexOf L contains L | add L add L | remove L remove L |
| im.Range | Constant space, a sequence of equally spaced integers | apply/last/head C | find L | ----- | |
Singly Linked List | im.Stream | Lazy list; memoized | apply L head/tail C | find L | #:: (prepend) C | filter L |
im.List | | | | m.ListBuffer <w) | | m.ListMap <w) | LIFO; structural sharing of tail so often Zero/Const memory cost of ops | :: (prepend) C :+ (append) L | ||||
last in C | apply L last C | find L | +=: (prepend) C += (append) C | -= L | ||
Insertion order | get L | contains L | += L | -= L | ||
im.ListMap | Insertion order | get L | contains L | + L | - L | |
m.LinkedList | None, deprecated |
| ||||
c.ConcurrentLinkedQueue | FIFO, unbounded & thread safe | peek C | contains L | offer C | poll C | |
c.LinkedBlockingQueue | FIFO; optional capacity bound | |||||
u.LinkedList | FIFO; implements List & Deque prepend, remove from interior insertion, removal & retrieval of elements at both ends | get L | indexOf L | add (to End) C | remove L | |
m.DoubleLinkedList | m.MutableList | <w) m.Queue <e) | deprecated
FIFO | deprecated
apply L head C last C | deprecated
find L | deprecated
+= (append) C +=: (prepent) C | deprecated
dequeue C | |
c.LinkedBlockingDeque | concurrent; optionally bounded | getFirst/Last C | contains L | add C | remove L | |
m.Stack <w) im.List im.Stack | None, deprecated since 2.11 | apply L | find L | push C | pop C | |
im.Queue | FIFO | apply L head/tail aC | find L | enqueue C | dequeue aC | |
Dual Queue | c.LinkedTransferQueue | FIFO; unbounded | ----- | contains L | offer C | poll C |
c.SynchronousQueue | No capacity, each insert op must wait for a corresponding remove op & vice versa | ----- | ----- | put C | take C | |
Chaining | u.Hashtable | Synchronized | get eC | containsKey eC | put eC | remove eC |
m.HashSet | faster than other sets | ----- |
contains eC |
+= eC |
-= eC | |
m.HashMap | faster than other maps | get eC | ||||
u.WeakHashMap | m.WeakHashMap <w) | Stores only weak references to its keys, key-value pairs will be GC'd if key no longer referenced outside | get Log | containsKey eC contains eC | put eC += eC | remove eC -= eC | |
u.IdentityHashMap | Uses reference-equality for compa-ring keys (and values), not object-equality | get C | get eC | put eC | remove eC | |
u.HashSet <w) u.HashMap | | Stores colliding values in a tree for at least 8 elements; faster than other sets/maps | ----- get C / Log | contains C containsKey C | add C put C Worst | remove C Worst | |
c.ConcurrentHashMap | Full concurrency of retrievals | get C | containsKey C | put C | remove C | |
| u.LinkedHashSet <e) u.HashSet | Insertion ordered | ----- | contains C | add C | remove C |
m.LinkedHashSet | Insertion ordered | ----- | contains C | += C | -= C | |
u.LinkedHashMap <e) u.HashMap
| Insertion ordered or access ordered (cache functionality). Iteration requires time proportional to the map size, not capacity (like u.HashMap). |
get C
| containsKey C | put C | remove C | |
m.LinkedHashMap | Insertion ordered | get C | contains C | += C | -= C | |
im.IntMap | Integer keys | get eC | contains eC | + eC | - eC | |
im.Vector | Locality; fast random selections & fast random functional updates | apply eC | find L | +: (prepend) eC :+ (append) eC | filter L | |
im.HashSet | Use hash codes; <5 elements stored as field objects | ----- |
contains eC |
+ eC |
- eC | |
im.HashMap | get eC | |||||
c.ConcurrentSkipListSet <w) c.ConcurrentSkipListMap | | Sorted order (via natural or custom ordering) | ----- | contains Log | add Log | remove Log | |
get Log | containsKey Log | put Log | remove Log | |||
| u.PriorityQueue | Natural or custom element ordering based on their values |
peek C |
contains L |
offer Log |
poll Log |
c.DelayQueue | Time-based scheduling queue | |||||
c.PriorityBlockingQueue | Unbounded; priority iteration order | |||||
m.PriorityQueue | Priority order for dequeue(All) | head C | find L | += Log | dequeue Log | |
u.TreeSet | Natural or custom element ordering based on their values; efficient iteration; min/max in Log | ----- | contains C | add C | remove C | |
u.TreeMap | get Log | containsKey Log | put Log | remove Log | ||
im.TreeSet | ----- | contains Log | + Log | - Log | ||
im.TreeMap | get Log | |||||
m.TreeSet | ----- | contains Log | += Log | -= Log | ||
m.TreeMap | get Log | |||||
Data Structure(s) | Implementation | Super Power(s) | (Random) Access | Search | Addition | Deletion |
Table2
Subclass and wrapping relationships between two classes are represented via <e) and <w). For example, the class java.util.Stack extends java.util.Vector and the Scala class scala.collection.mutable.StringBuilder wraps the Java class java.lang.StringBuilder in order to provide idiomatic functions and additional operations.
General features of Java & Scala structures
Several collection properties are not explicitly represented in the table above since they either apply to almost all elements or a simple rule exists:
Almost all data structures that store key/value pairs have the characters Map as part of their class name in the second column. The sole exception to this naming convention is java.util.Hashtable which is a retrofitted legacy class born before Java 2 that also stores key/value pairs.
Almost all Java Collections are mutable: They can be destroyed, elements can be removed from or added to them and their data values can be modified in-place, mutable structures can therefore loose their original/previous state. By contrast, Scala provides a dedicated immutable package (scala.collection.immutable) whose members, in contrast to scala.collection.mutable and the Java collections, cannot be changed in-place. All members of this immutable package are also persistent: Modifications will produce an updated version via structural sharing and/or path copying while also preserving the original version. Examples of immutable but non-persistent data structures from third party providers are mentioned below.
Mutability can lead to problems when concurrency comes into play. Most classes in Table 2 that do not have the prefix c. (abbreviating the package java.util.concurrent) are unsynchronized. In fact, one of the design decision made in the Java Collections Framework was to not synchronize most members of the java.util package since single-threaded or read-only uses of data structures are pervasive. In case synchronization for these classes is required, java.util.Collections provides a cascade of synchronized* methods that accept a given collection and return a synchronized, thread-safe version.
Due to the nature of immutability, the (always unsynchronized) immutable structures in Table 2 are thread-safe.
All entries in Table 2 are eager except for scala.collection.immutable.Stream which is a lazy list that only computes elements that are accessed.
Java supports the eight primitive data types byte, short, int, long, float, double, boolean and char. Things are a bit more complicated with Scala but the same effectively also applies there at the bytecode level. Both languages provide primitive and object arrays but the Java and Scala Collection libraries are object collections which always store object references: When primitives like 3 or 2.3F are inserted, the values get autoboxed so the respective collections will hold a reference to numeric objects (a wrapper class like java.lang.Integer) and not the primitive values themselves:
int[] javaArrayPrimitive = new int[]{1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11};
Integer[] javaArrayObject = new Integer[]{1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11};
// javaArrayPrimitive occupies just 64 Bytes, javaArrayObject 240 Bytes
List<Integer> javaList1 = new ArrayList<>(11); // initial capacity of 11
List<Integer> javaList2 = new ArrayList<>(11);
for (int i : javaArrayPrimitive)
javaList1.add(i);
for (int i : javaArrayObject)
javaList2.add(i);
// javaList1 is 264 bytes in size now as is javaList2
Similar results for Scala:
val scalaArrayPrimitive = Array[Int](1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11)
val scalaArrayObject = scalaArrayPrimitive.map(new java.lang.Integer(_))
// scalaArrayPrimitive occupies just 64 Bytes, scalaArrayObject 240 Bytes
val scalaBuffer1 = scalaArrayPrimitive.toBuffer
val scalaBuffer2 = scalaArrayObject.toBuffer
// scalaBuffer1 is 264 bytes in size now as is scalaBuffer2
Several third party libraries provide primitive collection support on the JVM allowing the 8 primitives mentioned above to be directly stored in data structures. This can have a big impact on the memory footprint – the creators of Apache Spark recommend in their official tuning guide to
Design your data structures to prefer arrays of objects, and primitive types, instead of the standard Java or Scala collection classes (e.g. HashMap). The fastutil library provides convenient collection classes for primitive types that are compatible with the Java standard library.
We will see below whether FastUtil is really the most suitable alternative.
Empirical Level
Hardly any concrete memory sizes and runtime numbers have been mentioned so far, these two measurements are in fact very different: Estimating memory usage is a deterministic task compared to runtime performance since the latter might be influenced by several non-deterministic factors, especially when operations run on an adaptive virtual machine that performans online optimizations.
Memory measurements for JVM objects
Determining the memory footprint of a complex object is far from trivial since JVM languages don’t provide a direct API for that purpose. Apache Spark has an internal function for this purpose that implements the suggestions of an older JavaWorld article. I ported the code and modified it a bit here so this memory measuring functionality can be conveniently used outside of Spark:
val objectSize = JvmSizeEstimator.estimate(new Object())
println(objectSize) // will print 16 since one flat object instance occupies 16 bytes
Measurements for the most important classes from Table 2 with different element types and element sizes are shown below. The number of elements will be 0, 1, 4, 16, 64, 100, 256, 1024, 4096, 10000, 16192, 65536, 100000, 262144, 1048576, 4194304, 10000000, 33554432 and 50000000 in all configurations. For data structures that store individual elements, the two element types are int and String. For structures operating with key/value pairs, the combinations int/int and float/String will be used. The raw sizes of these element types are 4 bytes in the case of an individual int or float (16 bytes in boxed form) and, since all Strings used here will be 8 characters long, 56 bytes per String object.
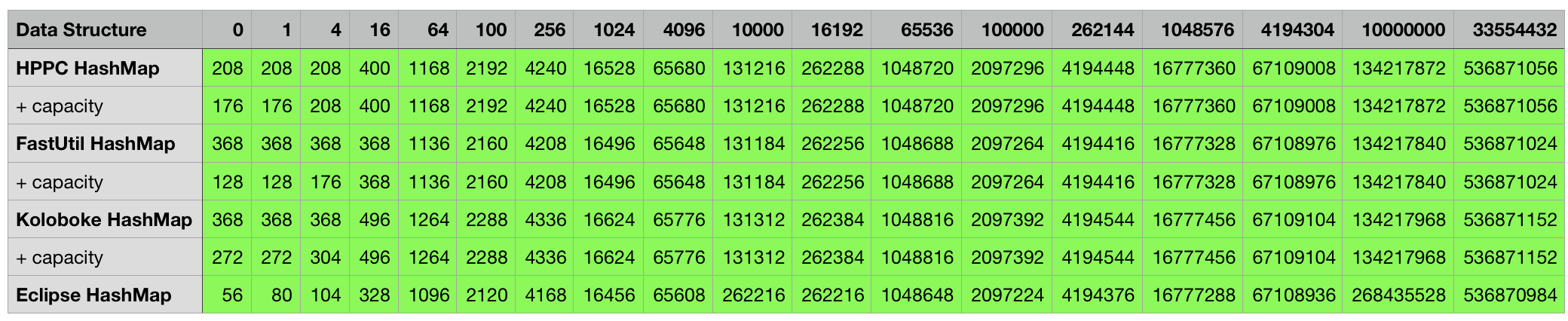
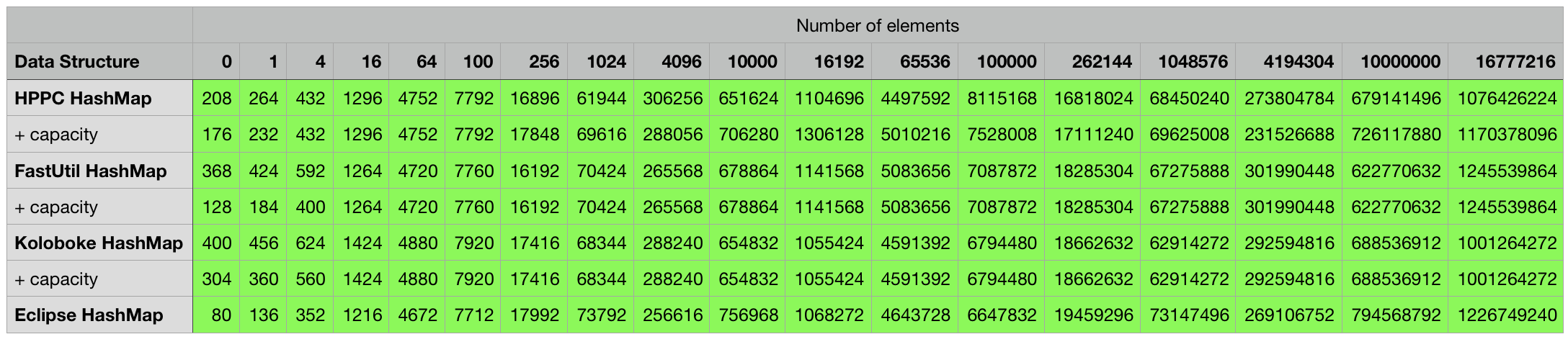
The same package abbreviations as in Table 2 above will be used for the Java/Scala classes under measurement. In addition, some classes from the following 3rd party libraries are also used in their latest edition at the time of writing:
- HPPC (0.8.1)
- Koloboke (1.0.0)
- fastutil (8.2.1)
- Eclipse Collections (9.2.0)
Concerning the environment, jdk1.8.0_171.jdk on MacOS High Sierra 10.13 was used. The JVM flag +UseCompressedOops can affect object memory sizes and was enabled here, it is enabled by default in Java 8.
Measurements of single element structures
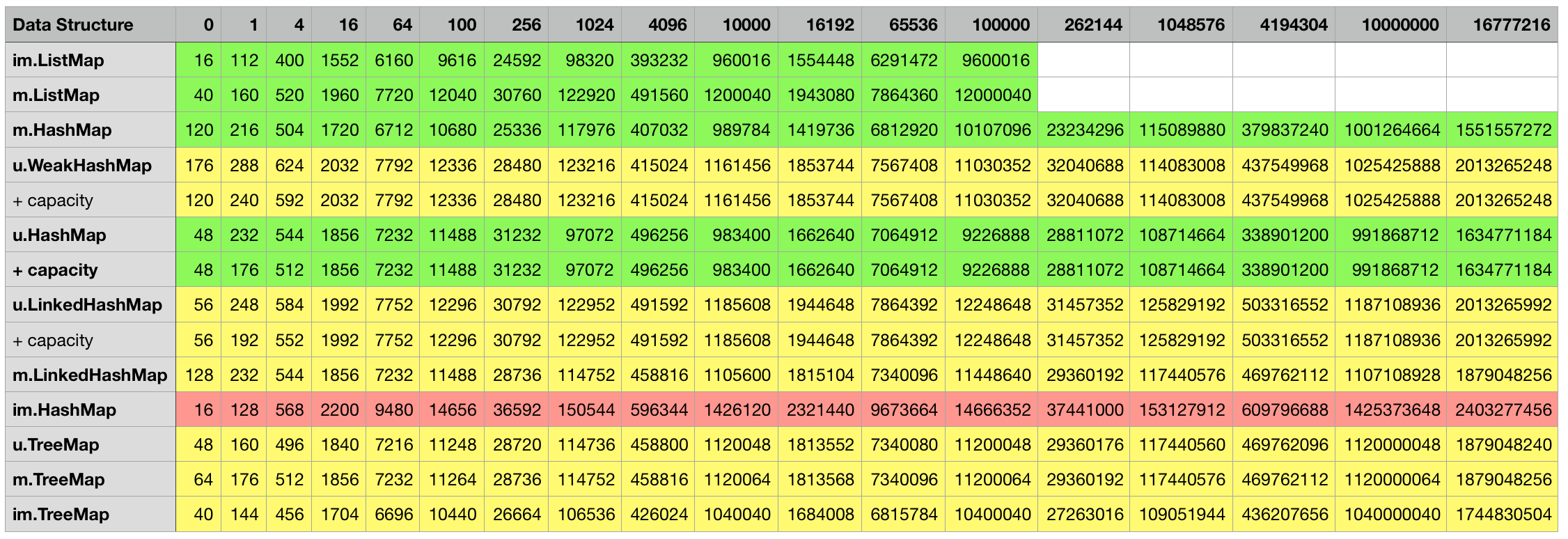
Below are the measurement results for the various combinations, every cell contains the object size in bytes for the particular data structure in the corresponding row filled with the number of elements indicated in the column. Some mutable classes provide the option to specify an initial capacity at construction time which can sometimes lead to a smaller overall object footprint after the structure is filled up. I included an additional + capacity row in cases where data structure in the previous row provides such an option and a difference could be measured.
Java/Scala structures storing integers:
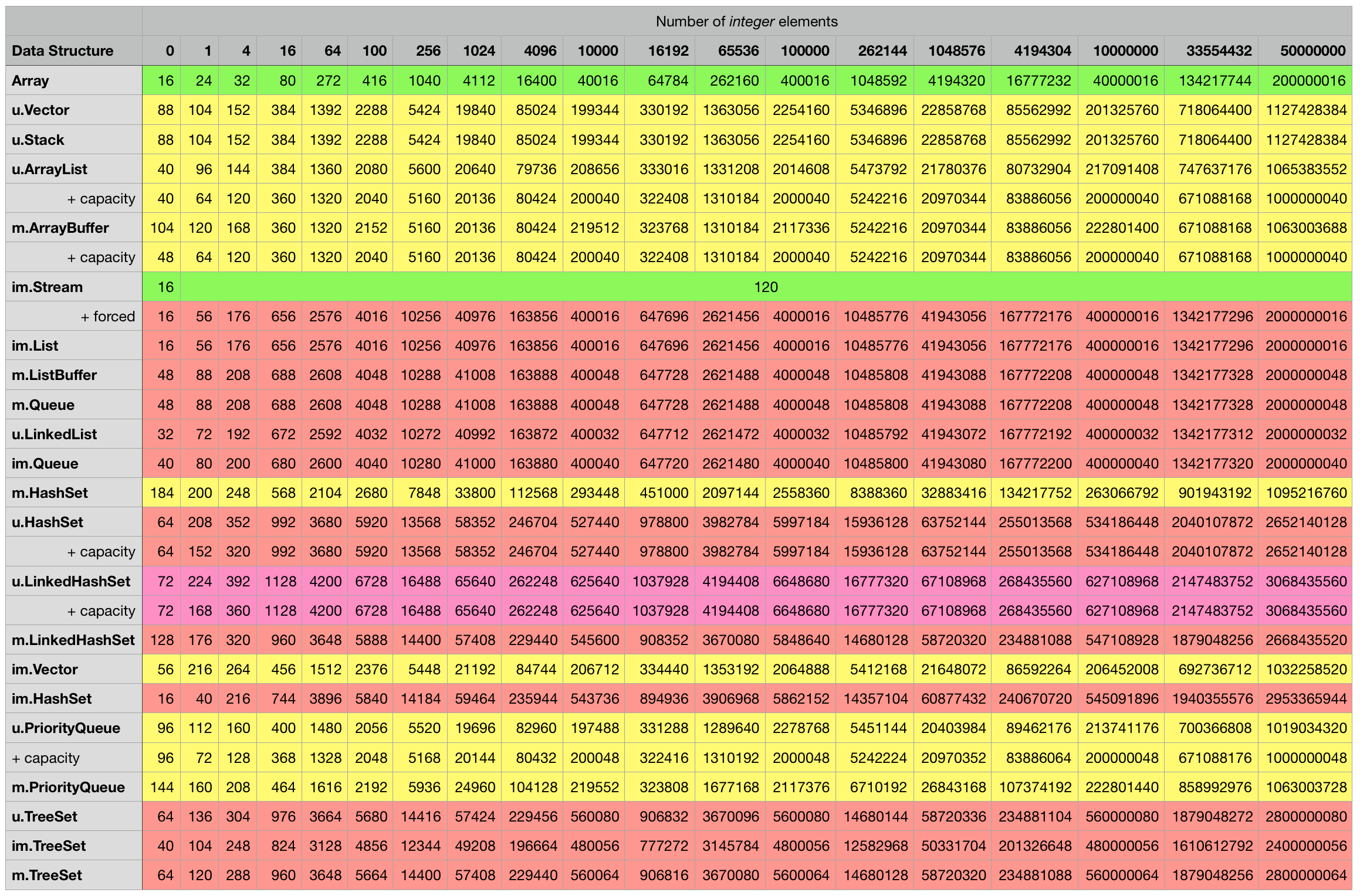
Java/Scala structures storing strings:
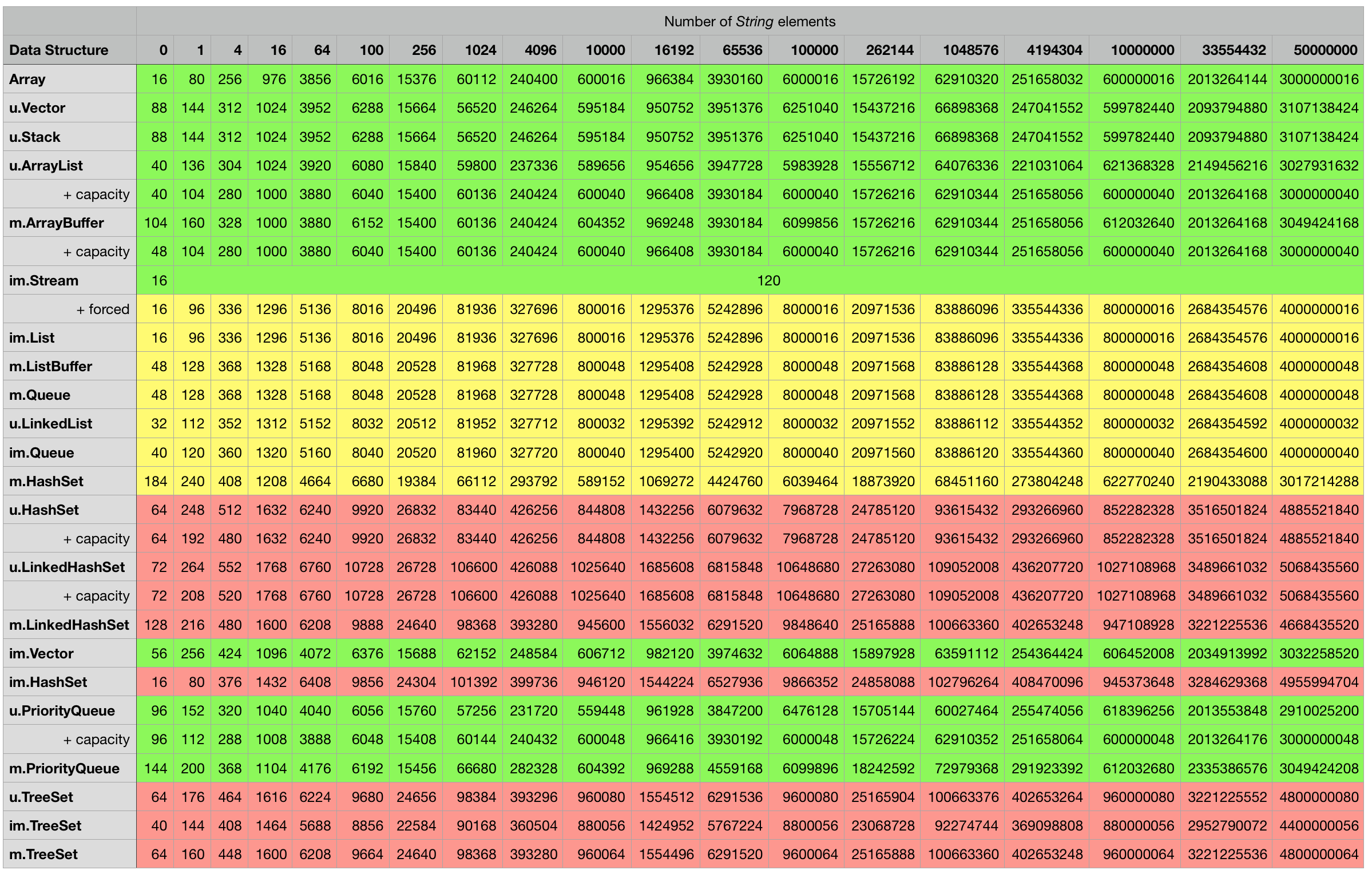
3rd party structures storing integers:
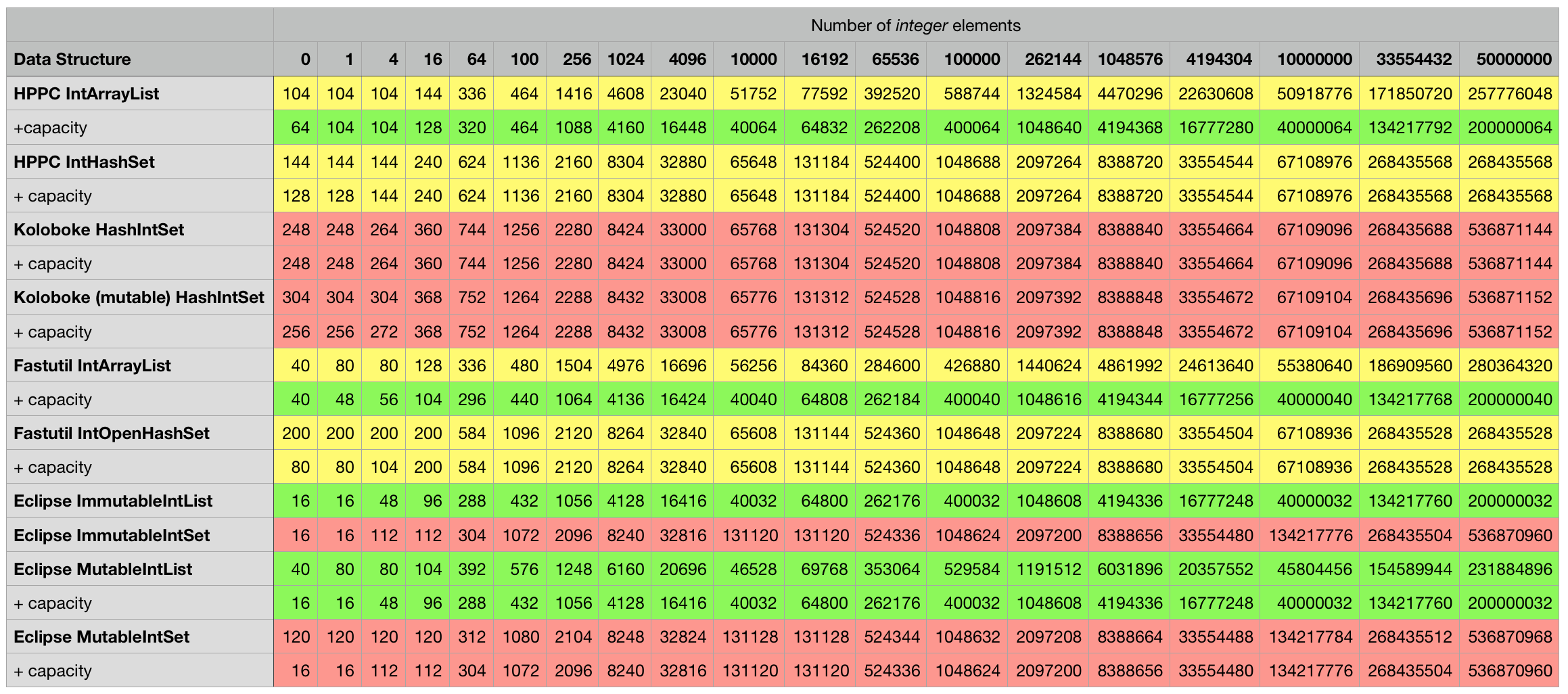
3rd party structures storing strings:
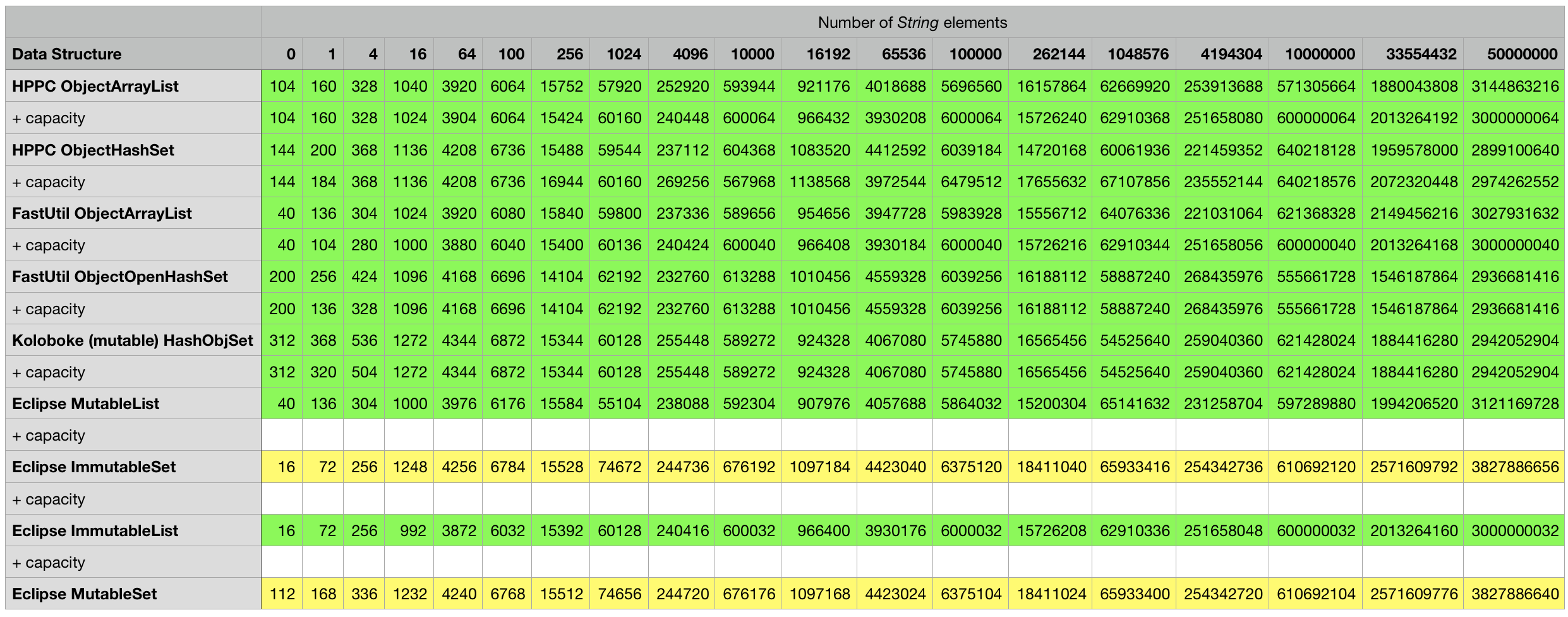
Measurements for key/value structures
For some mutable key/value structures like Java’s HashMap, a load factor that determines when to rehash can be specified in addition to an initial capacity. Similar to the logic in the previous tables, a row with + capacity will indicate that the data structure from the previous row was initialized using a capacity.
Java/Scala structures storing integer/integer pairs:
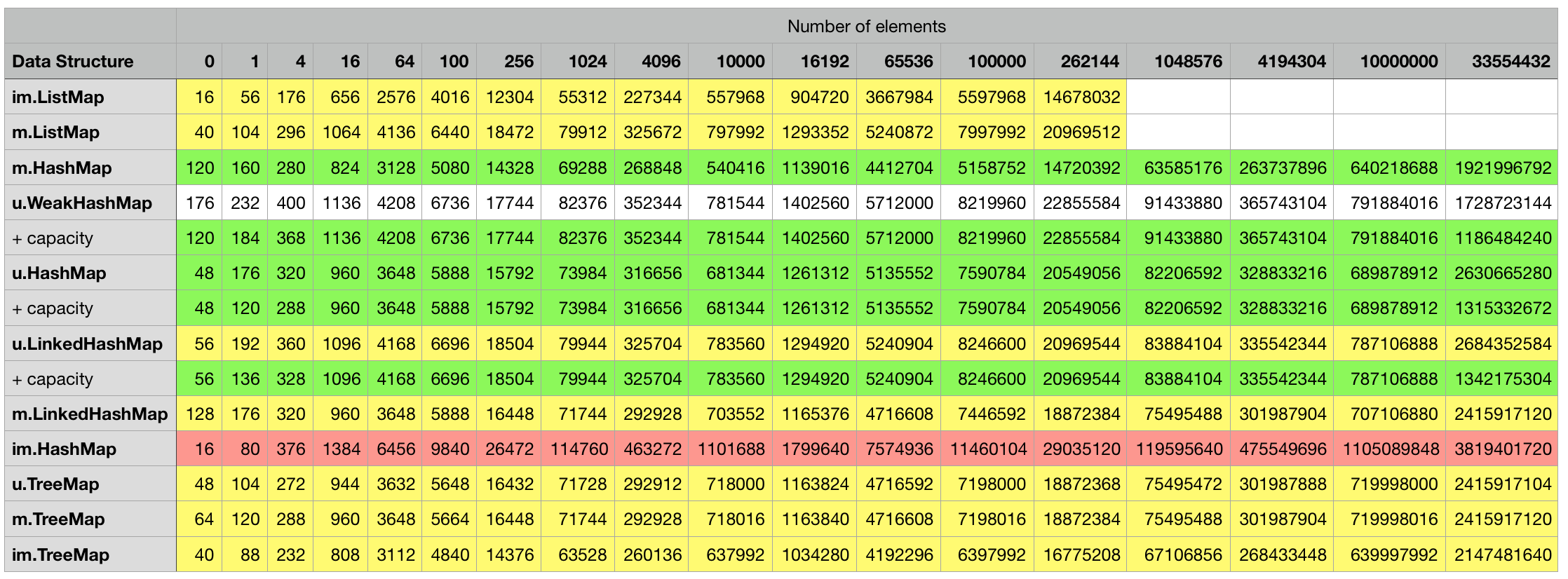
Java/Scala structures storing strings/float pairs:
3rd party structures storing integer/integer pairs:
3rd party structures storing strings/float pairs:
Operation benchmarking
| Under construction |