Made in London by me
Back to the index
First published here
§9 A deep dive into the Catalyst Optimizer
The Catalyst optimizer is a crucial component of Apache Spark. It optimizes structural queries – expressed in SQL, or via the DataFrame/Dataset APIs – which can reduce the runtime of programs and save costs. Developers often treat Catalyst as a black box that just magically works. Moreover, only a handful of resources are available that explain its inner workings in an accessible manner.
The Catalyst Pipeline
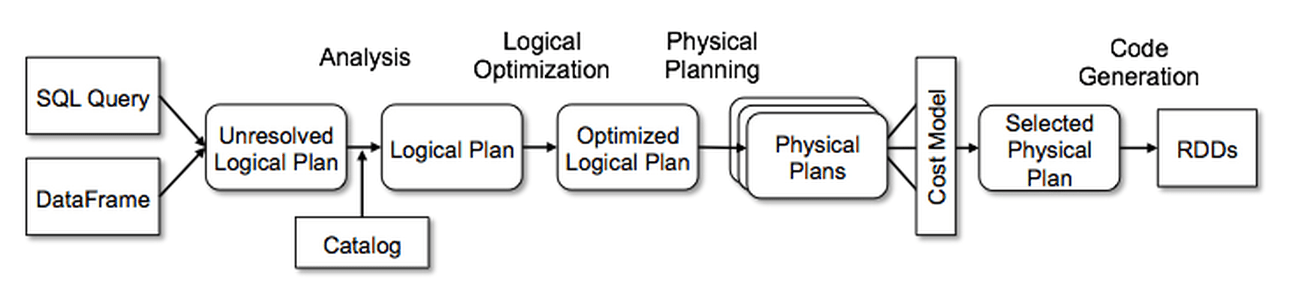
When discussing Catalyst, many presentations and articles reference this architecture diagram, which was included in the original blog post from Databricks that introduced Catalyst to a wider audience. The diagram has inadequately depicted the physical planning phase, and there is an ambiguity about what kind of optimizations are applied at which point.
The following sections explain Catalyst’s logic, the optimizations it performs, its most crucial constructs, and the plans it generates. In particular, the scope of cost-based optimizations is outlined. These were advertised as “state-of-art” when the framework was introduced, but this article will describe larger limitations. And, last but not least, I have redrawn the architecture diagram:
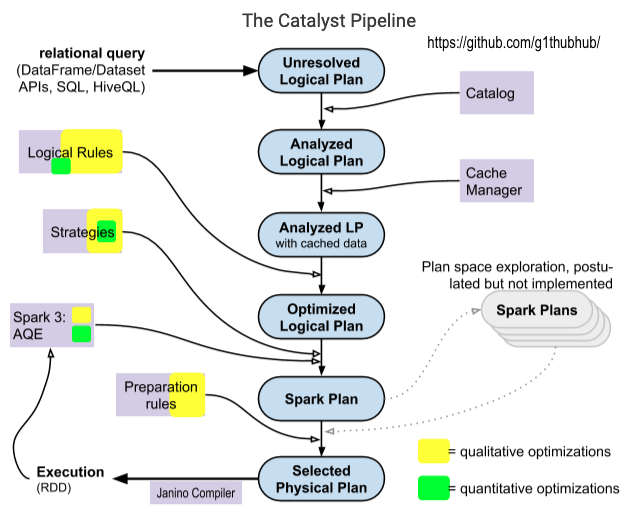
Diagram 1: The Catalyst pipeline
The input to Catalyst is a SQL/HiveQL query or a DataFrame/Dataset object which invokes an action to initiate the computation. This starting point is shown in the top left corner of the diagram. The relational query is converted into a high-level plan, against which many transformations are applied. The plan becomes better-optimized and is filled with physical execution information as it passes through the pipeline. The output consists of an execution plan that forms the basis for the RDD graph that is then scheduled for execution.
Nodes and Trees
Six different plan types are represented in the Catalyst pipeline diagram. They are implemented as Scala trees that descend from TreeNode. This abstract top-level class declares a children field of type Seq[BaseType]. A TreeNode can therefore have zero or more child nodes that are also TreeNodes in turn. In addition, multiple higher-order functions, such as transformDown, are defined, which are heavily used by Catalyst’s transformations.
This functional design allows optimizations to be expressed in an elegant and type-safe fashion; an example is provided below. Many Catalyst constructs inherit from TreeNode or operate on its descendants. Two important abstract classes that were inspired by the logical and physical plans found in databases are LogicalPlan and SparkPlan. Both are of type QueryPlan, which is a direct subclass of TreeNode.
In the Catalyst pipeline diagram, the first four plans from the top are LogicalPlans, while the bottom two – Spark Plan and Selected Physical Plan – are SparkPlans. The nodes of logical plans are algebraic operators like Join; the nodes of physical plans (i.e. SparkPlans) correspond to low-level operators like ShuffledHashJoinExec or SortMergeJoinExec. The leaf nodes read data from sources such as files on stable storage or in-memory lists. The tree root represents the computation result.
Transformations
An example of Catalyst’s trees and transformation patterns is provided below. We have used expressions to avoid verbosity in the code. Catalyst expressions derive new values and are also trees. They can be connected to logical and physical nodes; an example would be the condition of a filter operator.
The following snippet transforms the arithmetic expression –((11 – 2) * (9 – 5)) into - ((1 + 0) + (1 + 5)):
import org.apache.spark.sql.catalyst.expressions._
val firstExpr: Expression = UnaryMinus(Multiply(Subtract(Literal(11), Literal(2)), Subtract(Literal(9), Literal(5))))
val transformed: Expression = firstExpr transformDown {
case BinaryOperator(l, r) => Add(l, r)
case IntegerLiteral(i) if i > 5 => Literal(1)
case IntegerLiteral(i) if i < 5 => Literal(0)
}
The root node of the Catalyst tree referenced by firstExpr has the type UnaryMinus and points to a single child, Multiply. This node has two children, both of type Subtract.
The first Subtract node has two Literal child nodes that wrap the integer values 11 and 2, respectively, and are leaf nodes. firstExpr is refactored by calling the predefined higher-order function transformDown with custom transformation logic: The curly braces enclose a function with three pattern matches. They convert all binary operators, such as multiplication, into addition; they also map all numbers that are greater than 5 to 1, and those that are smaller than 5 to zero.
Notably, the rule in the example gets successfully applied to firstExpr without covering all of its nodes: UnaryMinus is not a binary operator (having a single child) and 5 is not accounted for by the last two pattern matches. The parameter type of transformDown is responsible for this positive behavior: It expects a partial function which might only cover subtrees (or not match any node) and returns “a copy of this node where rule has been recursively applied to it and all of its children (pre-order)”.
This example appears simple, but the functional techniques are powerful. At the other end of the complexity scale, for example, is a logical rule that, when it fires, applies a dynamic programming algorithm to refactor a join.
Catalyst Plans
The following (intentionally bad) code snippet will be the basis for describing the Catalyst plans in the next sections:
val result = session.read.option("header", "true").csv(outputLoc)
.select("letter", "index")
.filter($"index" < 10)
.filter(!$"letter".isin("h") && $"index" > 6)
result.show()
The complete program can be found here. Some plans that Catalyst generates when evaluating this snippet are presented in a textual format below; they should be read from the bottom up. A trick needs to be applied when using pythonic DataFrames, as their plans are hidden; this is described in our upcoming follow-up article, which also features a general interpretation guide for these plans.
Parsing and Analyzing
The user query is first transformed into a parse tree called Unresolved or Parsed Logical Plan:
'Filter (NOT 'letter IN (h) && ('index > 6))
+- Filter (cast(index#28 as int) < 10)
+- Project [letter#26, index#28]
+- Relation[letter#26,letterUppercase#27,index#28] csv
This initial plan is then analyzed, which involves tasks such as checking the syntactic correctness, or resolving attribute references like names for columns and tables, which results in an Analyzed Logical Plan.
In the next step, a cache manager is consulted. If a previous query was persisted, and if it matches segments in the current plan, then the respective segment is replaced with the cached result. Nothing is persisted in our example, so the Analyzed Logical Plan will not be affected by the cache lookup.
A textual representation of both plans is included below:
Filter (NOT letter#26 IN (h) && (cast(index#28 as int) > 6))
+- Filter (cast(index#28 as int) < 10)
+- Project [letter#26, index#28]
+- Relation[letter#26,letterUppercase#27,index#28] csv
Up to this point, the operator order of the logical plan reflects the transformation sequence in the source program, if the former is interpreted from the bottom up and the latter is read, as usual, from the top down. A read, corresponding to Relation, is followed by a select (mapped to Project) and two filters. The next phase can change the topology of the logical plan.
Logical Optimizations
Catalyst applies logical optimization rules to the Analyzed Logical Plan with cache data. They are part of rule groups which are internally called batches. There are 25 batches with 109 rules in total in the Optimizer (Spark 2.4.7). Some rules are present in more than one batch, so the number of distinct logical rules boils down to 69. Most batches are executed once, but some can run repeatedly until the plan converges or a predefined maximum number of iterations is reached. Our program CollectBatches can be used to retrieve and print this information, along with a list of all rule batches and individual rules; the output can be found here.
Major rule categories are operator pushdowns/combinations/replacements and constant foldings. Twelve logical rules will fire in total when Catalyst evaluates our example. Among them are rules from each of the four aforementioned categories:
- Two applications of
PushDownPredicatethat move the two filters before the column selection - A
CombineFiltersthat fuses the two adjacent filters into one - An
OptimizeInthat replaces the lookup in a single-element list with an equality comparison - A
RewritePredicateSubquerywhich rearranges the elements of the conjunctive filter predicate thatCombineFilterscreated
These rules reshape the logical plan shown above into the following Optimized Logical Plan:
Project [letter#26, index#28], Statistics(sizeInBytes=162.0 B)
+- Filter ((((isnotnull(index#28) && isnotnull(letter#26)) && (cast(index#28 as int) < 10)) && NOT (letter#26= h)) &&
(cast(index#28 as int) > 6)), Statistics(sizeInBytes=230.0 B)
+- Relation[letter#26,letterUppercase#27,index#28] csv, Statistics(sizeInBytes=230.0 B
Quantitative Optimizations
Spark’s codebase contains a dedicated Statistics class that can hold estimates of various quantities per logical tree node. They include:
- Size of the data that flows through a node
- Number of rows in the table
- Several column-level statistics:
- Number of distinct values and nulls
- Minimum and maximum value
- Average and maximum length of the values
- An equi-height histogram of the values
Estimates for these quantities are eventually propagated and adjusted throughout the logical plan tree. A filter or aggregate, for example, can significantly reduce the number of records the planning of a downstream join might benefit from using the modified size, and not the original input size, of the leaf node.
Two estimation approaches exist:
- The simpler, size-only approach is primarily concerned with the first bullet point, the physical size in bytes. In addition, row count values may be set in a few cases.
- The cost-based approach can compute the column-level dimensions for
Aggregate,Filter,Join, andProjectnodes, and may improve their size and row count values.
For other node types, the cost-based technique just delegates to the size-only methods. The approach chosen depends on the spark.sql.cbo.enabled property. If you intend to traverse the logical tree with a cost-based estimator, then set this property to true. Besides, the table and column statistics should be collected for the advanced dimensions prior to the query execution in Spark. This can be achieved with the ANALYZE command. However, a severe limitation seems to exist for this collection process, according to the latest documentation:
currently statistics are only supported for Hive Metastore tables where the command ANALYZE TABLE
COMPUTE STATISTICS noscan has been run
The estimated statistics can be used by two logical rules, namely CostBasedJoinReorder and ReorderJoin (via StarSchemaDetection), and by the JoinSelection strategy in the subsequent phase, which is described further below.
The Cost-Based Optimizer
A fully fledged Cost-Based Optimizer (CBO) seems to be a work in progress, as indicated here:
For cost evaluation, since physical costs for operators are not available currently, we use cardinalities and sizes to compute costs The CBO facilitates the
CostBasedJoinReorderrule and may improve the quality of estimates; both can lead to better planning of joins. Concerning column-based statistics, only the two count stats (distinctCountandnullCount) appear to participate in the optimizations; the other advanced stats may improve the estimations of the quantities that are directly used.
The scope of quantitative optimizations does not seem to have significantly expanded with the introduction of the CBO in Spark 2.2. It is not a separate phase in the Catalyst pipeline, but improves the join logic in several important places. This is reflected in the Catalyst optimizer diagram by the smaller green rectangles, since the stats-based optimizations are outnumbered by the rule-based/heuristic ones.
The CBO will not affect the Catalyst plans in our example for three reasons:
- The property spark.sql.cbo.enabled is not modified in the source code and defaults to false.
- The input consists of raw CSV files for which no table/column statistics were collected.
- The program operates on a single dataset without performing any joins.
The textual representation of the optimized logical plan shown above includes three Statistics segments which only hold values for sizeInBytes. This further indicates that size-only estimations were used exclusively; otherwise attributeStats fields with multiple advanced stats would appear.
Physical Planning
The optimized logical plan is handed over to the query planner (SparkPlanner), which refactors it into a SparkPlan with the help of strategies — Spark strategies are matched against logical plan nodes and map them to physical counterparts if their constraints are satisfied. After trying to apply all strategies (possibly in several iterations), the SparkPlanner returns a list of valid physical plans with at least one member.
Most strategy clauses replace one logical operator with one physical counterpart and insert PlanLater placeholders for logical subtrees that do not get planned by the strategy. These placeholders are transformed into physical trees later on by reapplying the strategy list on all subtrees that contain them.
As of Spark 2.4.7, the query planner applies ten distinct strategies (six more for streams). These strategies can be retrieved with our CollectStrategies program. Their scope includes the following items:
- The push-down of filters to, and pruning of, columns in the data source
- The planning of scans on partitioned/bucketed input files
- The aggregation strategy (
SortAggregate,HashAggregate, orObjectHashAggregate) - The choice of the join algorithm (broadcast hash, shuffle hash, sort merge, broadcast nested loop, or cartesian product)
The SparkPlan of the running example has the following shape:
Project [letter#26, index#28]
+- Filter ((((isnotnull(index#28) && isnotnull(letter#26)) && (cast(index#28 as int)<10)) && NOT (letter#26=h)) && (cast(index#28 as int)>6))
+- FileScan csv [letter#26,index#28] Batched: false, Format: CSV, Location: InMemoryFileIndex[file:/example], PartitionFilters: [],
PushedFilters: [IsNotNull(index), IsNotNull(letter), Not(EqualTo(letter,h))], ReadSchema: struct<letter:string,index:string>
A DataSource strategy was responsible for planning the FileScan leaf node and we see multiple entries in its PushedFilters field. Pushing filter predicates down to the underlying source can avoid scans of the entire dataset if the source knows how to apply them; the pushed IsNotNull and Not(EqualTo) predicates will have a small or nil effect, since the program reads from CSV files and only one cell with the letter h exists.
The original architecture diagram depicts a Cost Model that is supposed to choose the SparkPlan with the lowest execution cost. However, such plan space explorations are still not realized in Spark 3.01; the code trivially picks the first available SparkPlan that the query planner returns after applying the strategies.
{kind=link}
A simple, “localized” cost model might be implicitly defined in the codebase by the order in which rules and strategies and their internal logic get applied. For example, the JoinSelection strategy assigns the highest precedence to the broadcast hash join. This tends to be the best join algorithm in Spark when one of the participating datasets is small enough to fit into memory. If its conditions are met, the logical node is immediately mapped to a BroadcastHashJoinExec physical node, and the plan is returned. Alternative plans with other join nodes are not generated.
Physical Preparation
The Catalyst pipeline concludes by transforming the Spark Plan into the Physical/Executed Plan with the help of preparation rules. These rules can affect the number of physical operators present in the plan. For example, they may insert shuffle operators where necessary (EnsureRequirements), deduplicate existing Exchange operators where appropriate (ReuseExchange), and merge several physical operators where possible (CollapseCodegenStages).
The final plan for our example has the following format:
(1) Project [letter#26, index#28]
+- *(1)Filter((((isnotnull(index#28) && isnotnull(letter#26)) && (cast(index#28 as int)<10)) && NOT(letter#26=h)) && (cast(index#28 as int)>6))
+- *(1) FileScan csv [letter#26,index#28] Batched: false, Format: CSV, Location: InMemoryFileIndex[file:/example], PartitionFilters: [],
PushedFilters: [IsNotNull(index), IsNotNull(letter), Not(EqualTo(letter,h))], ReadSchema: struct<letter:string,index:string>
This textual representation of the Physical Plan is identical to the preceding one for the Spark Plan, with one exception: Each physical operator is now prefixed with a *(1). The asterisk indicates that the aforementioned CollapseCodegenStages preparation rule, which “compiles a subtree of plans that support codegen together into a single Java function,” fired.
The number after the asterisk is a counter for the CodeGen stage index. This means that Catalyst has compiled the three physical operators in our example together into the body of one Java function. This comprises the first and only WholeStageCodegen stage, which in turn will be executed in the first and only Spark stage. The code for the collapsed stage will be generated by the Janino compiler at run-time.
Adaptive Query Execution in Spark 3
One of the major enhancements introduced in Spark 3.0 is Adaptive Query Execution (AQE), a framework that can improve query plans during run-time. Instead of passing the entire physical plan to the scheduler for execution, Catalyst tries to slice it up into subtrees (“query stages”) that can be executed in an incremental fashion.
The adaptive logic begins at the bottom of the physical plan, with the stage(s) containing the leaf nodes. Upon completion of a query stage, its run-time data statistics are used for reoptimizing and replanning its parent stages. The scope of this new framework is limited: The official SQL guide states that “there are three major features in AQE, including coalescing post-shuffle partitions, converting sort-merge join to broadcast join, and skew join optimization.” A query must not be a streaming query and its plan must contain at least one Exchange node (induced by a join for example) or a subquery; otherwise, an adaptive execution will not be even attempted – if a query satisfies the requirements, it may not get improved by AQE.
A large part of the adaptive logic is implemented in a special physical root node called AdaptiveSparkPlanExec. Its method getFinalPhysicalPlan is used to traverse the plan tree recursively while creating and launching query stages. The SparkPlan that was derived by the preceding phases is divided into smaller segments at Exchange nodes (i.e., shuffle boundaries), and query stages are formed from these subtrees. When these stages complete, fresh run-time stats become available, and can be used for reoptimization purposes.
A dedicated, slimmed-down logical optimizer with just one rule, DemoteBroadcastHashJoin, is applied to the logical plan associated with the current physical one. This special rule attempts to prevent the planner from converting a sort merge join into a broadcast hash join if it detects a high ratio of empty partitions. In this specific scenario, the first join type will likely be more performant, so a no-broadcast-hash-join hint is inserted.
The new optimized logical plan is fed into the default query planner (SparkPlanner) which applies its strategies and returns a SparkPlan. Finally, a small number of physical operator rules are applied that takes care of the subqueries and missing ShuffleExchangeExecs. This results in a refactored physical plan, which is then compared to the original version. The physical plan with the lowest number of shuffle exchanges is considered cheaper for execution and is therefore chosen.
When query stages are created from the plan, four adaptive physical rules are applied that include CoalesceShufflePartitions, OptimizeSkewedJoin, and OptimizeLocalShuffleReader. The logic of AQE’s major new optimizations is implemented in these case classes. Databricks explains these in more detail here. A second list of dedicated physical optimizer rules is applied right after the creation of a query stage; these mostly make internal adjustments.
The last paragraph has mentioned four adaptive optimizations which are implemented in one logical rule (DemoteBroadcastHashJoin) and three physical ones (CoalesceShufflePartitions, OptimizeSkewedJoin, and OptimizeLocalShuffleReader). All four make use of a special statistics class that holds the output size of each map output partition. The statistics mentioned in the Quantitative Optimization section above do get refreshed, but will not be leveraged by the standard logical rule batches, as a custom logical optimizer is used by AQE.
This article has described Spark’s Catalyst optimizer in detail. Developers who are unhappy with its default behavior can add their own logical optimizations and strategies or exclude specific logical optimizations. However, it can become complicated and time-consuming to devise customized logic for query patterns and other factors, such as the choice of machine types, may also have a significant impact on the performance of applications. The next article will focus on practical aspects of the Catalyst plans.